AI-detection tools for GPT3 (and similar LLMs) are largely pure nonsense! Both AI-lovers and AI-haters need to wake up. Read on!
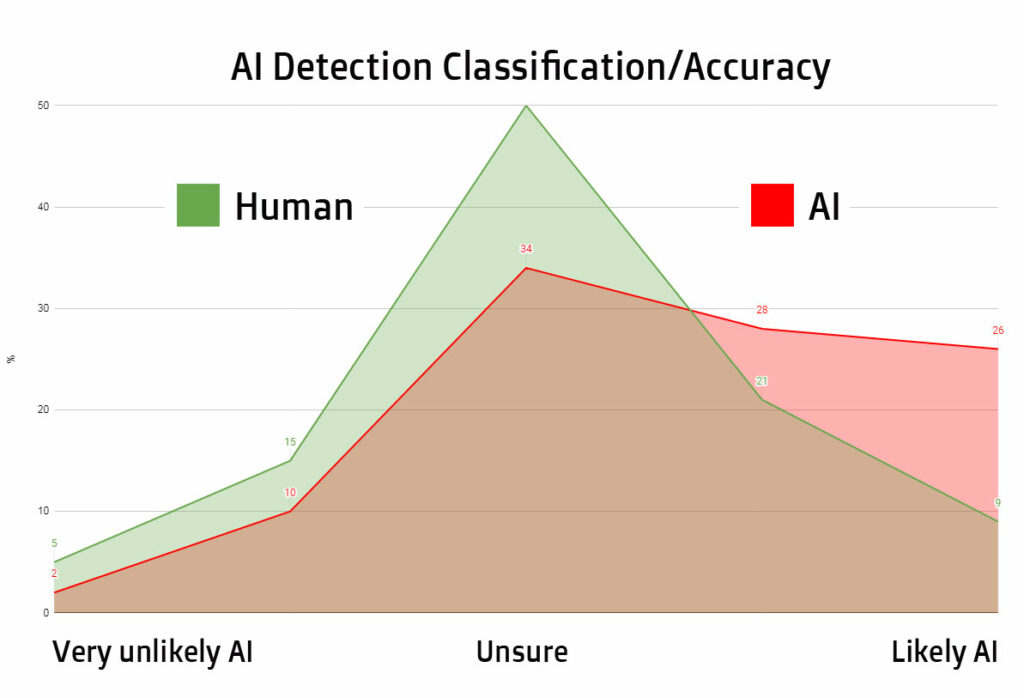
A perfect AI-detector would show all the human (green) to the far left, and all the AI (red) to the far right.
Overlap means inaccuracy and uncertainty. As you see, the majority of human-made and AI-made is overlapping.
And this is how “good” AI-detectors are: Mostly useless, but as a bonus you don’t know when they are useless.
It’s not necessarily because they are poorly made, but rather that they aim to achieve something that is not achievable.
Quick, relevant background:
I was studying neural networks in university as far back as in 2002. I’ve been “playing” with content generation since 2004. I have created AI-based software in this niche. I am confident that I have more expertise on the subject than at least 99.9% of people that use AI. (Sorry for the arrogant tone, I’m rather humble, but I want to put things in perspective for you.)
My objection with AI-detection tools: False positives
The results from tools are based on probability and chance; and they have much worse accuracy than you think.
By bad accuracy I mean both at not detecting AI but also at wrongly labeling human content as AI-made, i.e. false positive (computer talk for “wrongly accused”).
If you are a content writer you should definitely care about this.
False positives happen in most systems, but it’s the overwhelming degree to which it happens with the AI-detection tools that make them (in my opinion) useless.
Closer to random guessing than reliable results
In this article, I will present you data that shows that 30% of human-made is misclassified as AI.
50% would be equivalent to random guessing. 30% is more than halfway to random guessing.
At some point the tool creators have to face reality and say “Sorry, we have no clue”. At the very least they should be presented with a massive warning.
The detection tool creators are not necessarily “evil”. I do think many of them are simply unaware of the massive scope of the problem that they try to attack.
However, detectors that cost money are, in my opinion, a waste of money. (And I suspect that the paid services know this.)
If you are an elite copywriter (or an expert in any field), think about how you feel about the vast majority of content writers. You know that most of them don’t even understand what great copywriting means. – This might be true of creators of “AI-detectors”.
This is how inaccurate AI-detectors are
Time to burst your bubble…
For now, I will only talk about OpenAI’s detector, as they are the creator of ChatGPT, and also the base for almost all AI-content tools such as Jasper.ai and more. I will comment other detectors later.
OpenAI have data on accuracy of their detector. They simply make large sets of tests where they feed it text they know are made with AI (e.g. ChatGPT outputs) vs text they know where made by humans (books, magazines, forums.)
This is what OpenAI writes about the various classifications used by their AI detection tool. :
“Very unlikely to be AI-generated” corresponds to a classifier threshold of <0.1. About 5% of human-written text and 2% of AI-generated text from our challenge set has this label.
So, of all content they tested, “only” 2% of AI texts get the highest/best score (in terms of being unlikely AI). But also only 5% of human.
I think that many people expected the human to be 50% or maybe even 80%. Sorry to disappoint you, but this is why you need to wake up.
Simple math (2/(5+2)) tells us that 29% of “very unlikely AI” is actually AI.
(My software, ROARgen, get about 40-70% of all it’s AI-content classified as “very unlikely AI”. Why? Because it’s possible to methodically avoid attributes that the detectors are looking for.)
“Unlikely to be AI-generated” corresponds to a classifier threshold between 0.1 and 0.45. About 15% of human-written and 10% of AI-generated text from our challenge set has this label.
At this level, the differences between human and AI are even smaller. 40% of “unlikely AI” is AI.
“Unclear if it is AI written” corresponds to a classifier threshold between 0.45 and 0.9. About 50% of human-written text and 34% of AI-generated text from our challenge set has this label.
The interesting thing here is that this is the largest classification. Half of all human content is classified with an unuseful “we don’t know”.
“Possibly AI-generated” corresponds to a classifier threshold between 0.9 and 0.98. About 21% of human-written text and 28% of AI-generated text from our challenge set has this label.
Here it gets scary. 21% of all human is classified as “likely AI”. Imagine having that discussion with a client.
I see a lot of clients on Upwork “warning” that content will be subjected to detectors.
“Likely AI-generated” corresponds to a classifier threshold >0.98. About 9% of human-written text and 26% of AI-generated text from our challenge set has this label.
The 26% is good. The horrible part is that 9% of human-made content is getting the worst classification.
Simple math (9/(26+9)) tells us that 25.7% of “Likely AI” is actually human-made.
9% of human content gets the strongest misclassification as AI, while only 2% of AI gets the strongest misclassification as human.
Human writers at greater risk
The above shows that there is a very strong tendency for the detector to be more wrong about human-made than about AI-made.
15% of AI-content is classified as “unlikely” or “very unlikely” AI-generated.
30% of human-made is classified as “possibly” or “likely” AI-made. Human content is at 2x higher risk of misclassification than AI.
Do you want to fire a writer with 30% risk that they are innocent of copy/pasting from ChatGPT?
In other words, it’s the human writers that are at risk here.
This is my entire point with detectors: They come with massive side-effects so great that they are pointless.
Not all human nor all AI content is created equal
The classification does depend on writing style, overall quality etc. I have not investigated the matter, but believe that good writers are likely to be at less risk of misclassification.
However, the same goes for AI-generated text, meaning “good” AI-generated text is also less likely to get accurately classified as AI (which is why I mentioned my software before.)
Other detectors
Other, more reliable detectors will not come from some random programmer, so stop sharing those services! I know you mean well, but you are actually making the misinformation worse.
You don’t know their method, which is very likely very simple. Google and other large institutions will have a better chance, but even they struggle with this.
A detector that seems to “catch” AI more effectively will also be more likely to wrongly flag human-made as AI.
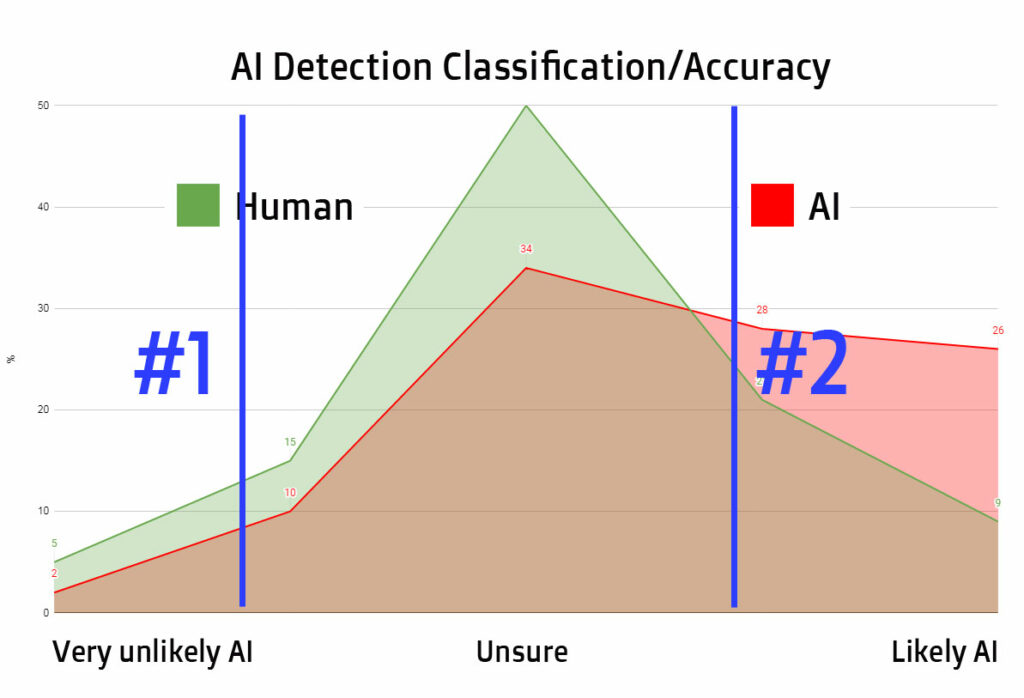
In the image above I am showing two blue lines. A “strict” AI-detector should prefer #1 over #2 as criteria for “AI-made”.
A detector that values less misclassifications of human-made as AI would choose #2. In both cases the margin of error grows for either human or AI.
So which “necessary evil” do you prefer? To wrongly accuse or allow for some slippage?
This is not a straightforward choice. I don’t have the answer about what should be done. But I do know that the sense effectiveness that the AI-detection tools try to insinuate is just plainly wrong!
You can create a tool that classifies all AI as AI but at the cost of classifying all human as AI too. As long as all your test are on texts that you made with ChatGPT (or some other service) you will think the detector is the best ever.
Worth repeating: The reason why I used OpenAI’s detector as an example is because they are at least transparent about the context and complexity.
The other detectors have an incentive to convince you that they are accurate and effective – to make you buy some premium service or show ads to you.
They have the incentives to keep you in the dark regarding how unreliable they are.
Why so difficult to detect AI?
There will never be an AI-detector that is truly 100% correct. There is always a chance that a human will write a text that is “obviously AI”.
Even with larger texts this can happen.
The current development of AI aims to mimic humans better, not the other way around.
We humans mimic each-other too. We are not born with some devine ability to speak which can’t be replicated. We actually learn language in similar way as LLMs (Large Language Models).
We don’t follows rules, we construct sentences based on what “feels” correct. We can construct sentences that sound fantastic but are factually completely wrong… just like LLMs.
A native English speaker can often identify a non-native speaker. Same with identify an AI. But at a certain level the non-native sounds native. At a certain point AI start to sound very human, to the point where it’s indistinguishable.
(I am not a native English speaker. I’ve never lived in an English speaking country. English is my third language. Did you notice?)
If you claim you can always identify AI, you must state your case in a very direct and precise way. (I know you can’t by I urge you to try.)
“Google will figure it out” is an unacceptable and really gullible thing to say. – I see tons of people writing this in online discussions. Writing such things just shows that you have no understanding of the topic. Stop blindly worshipping Google. It’s not a deity.
Cryptographic Watermarking
For text, this is a method for creating patterns using letters, punctuations, word positions, sentence length (and many other things) to allow for “watermarking” a text. The idea is that whoever put those patterns there will know what to look for and be able to fairly accurately to determine that the text is AI, but the you won’t know if there even is a watermarking present.
I says “fairly accurately” because there is always a random chance that a human wrote a text that, by pure coincidence, has a pattern match that of an AI.
Google uses cryptographic watermarking for Google Translate (which is why copy/pasting the translations is a bad idea for SEO even if the translations are good.)
OpenAI have said they will implement it. But they have also said that there are methods to distort it (render it useless.)
Final Words
If you want to use AI-detectors, then fine. Do that. But more as a toy rather than a serious tool.
***
I am not taking a stance for or against AI-generation. But I am taking a stance against the idea that AI-detectors are reliable tools when making important decisions.
***
Keep in mind that this entire article refers to GPT3 and higher.